
Extracting data from PDFs: No Silver Bullet
PDF or Portable Document Format is a format for storing documents. Extracting information from PDFs to computer understandable form is a challenge. In this post I’m gonna explore what I have learned while using multimodal GPT-4-vision in this task.

Introduction
Markdown is a data format that Large Language Models (LLMs) today in 2024 understands and produces very well. Translating a PDF to markdown, allows a LLM to understand a document.
Multimodal models allow taking input as not just text but also images and soon several other data types.
This led me to think about an idea of using a multimodal model (GPT-4-vision) to take multiple views to a PDF as an input: texts, tables and page as image. Producing one coherent view to the same data in markdown as the output.
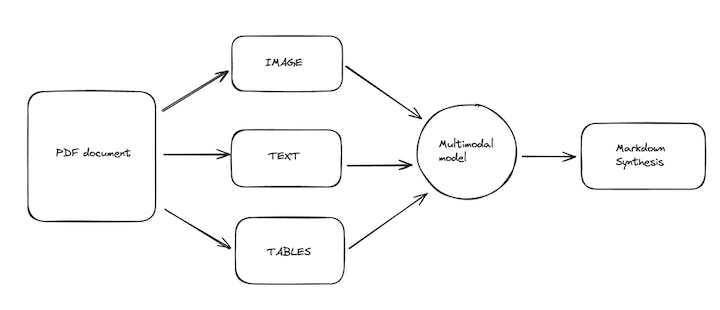
Based on my experiments, there are new things that you can extract out of PDFs with this approach. There are also new problems that this approach brings for us to tackle.
Tools for data extraction from PDFs
When extracting data from PDFs the information can be in a picture or in a format that the extractor sees or places incorrectly. Direct text extraction with tools like PyPDF gives a partial representation of the data on a PDF. Tools like Tesseract OCR Engine (OCR stands for optical character recognition) on the other hand try to take the texts out from a picture. This can fail to identify parts of the text or misinterpret them. Camelot is a more focused tool to extract tabular data from PDFs. This is different from the others before as this preserves a 2 dimensional representation of the data. This is only a partial representation of the data as not all data is in tables. All the tools mentioned above focus on extracting text and can not handle abstract images such as graphs or other visualizations.
Fisher Globe Valve Instruction Manual
While experimenting with PDF data I encountered a valve instruction manual from Emerson. It seemed like a really hard PDF to extract information from. The document is full of tables and technical drawings. The tables in the document contain multiple levels of headers on both row and column directions. I looked at different tools for my GPT-4-vision based approach. I ended up with 3 views to a PDF page: Image of the whole PDF page. This is the most complete representation of the data in the PDF page. PyPDF extracted texts from the PDF page. This gives exact texts in a one dimensional format. Camelot extracted tabular data from the PDF page. This gives a 2 dimensional view to data and helps in aligning table column and row values. The first experiments were with the image as input only. This showed that there are limits in what the multimodal model can see in the image. It can easily miss texts, read them incorrectly or decide to focus on graphical details that are not relevant for the content. On the positive side this showed that the model can describe visuals even if they are not text. I then added PyPDF. This gave the extraction a lot more accuracy with texts. Changing from outputs like “This is a page of text” to the actual content. For the tables in the data I was still getting misses. PyPDF output is not always capturing table structures. This can then misalign or hide information. Including Camelot fixed these almost completely.
Results: Hits and Misses
Overall the resulting markdown documents seem to be good quality. They represent the documents in a detailed level including descriptions of visual elements in there. One caveat with this approach is that it currently takes a considerable amount of time to process a large document. Taking roughly a minute per page to process. Most of the time goes into OpenAI GPT-4-vision model execution. There are interesting classes of new problems that I have seen in this approach.
- Replicating the data with erroneous content sometimes is hard. The LLM might decide to fix something that it sees as wrong in the original document.
- Replicating the data where views are different can lead to wrong conclusions. This can show up as wrong data in the extracted version.
- Results will change. If you run the same document through the process again you may get different descriptions for the same image and different formatting for the same data etc.
- There are limits to the visual data extractions. It is not the most precise tool and in cases where PyPDF and Camelot can’t help, these limits can be very visible as only a shallow understanding of a graph for example.
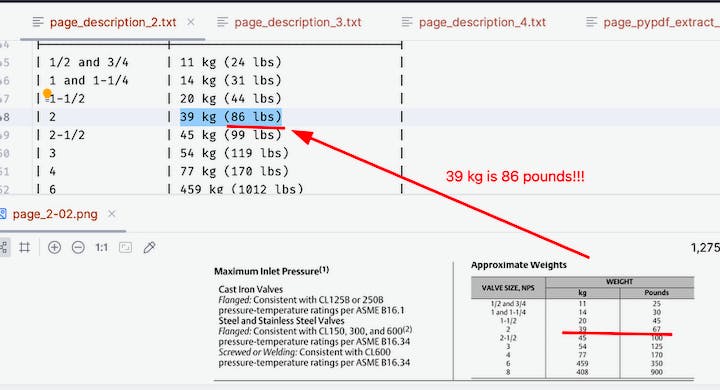
Example where LLM has corrected document error while translating the document:
Comparing the method to LlamaParse
LlamaIndex recently announced LlamaCloud and LlamaParse. https://blog.llamaindex.ai/introducing-llamacloud-and-llamaparse-af8cedf9006b
I wanted to see how the PDF document I had would be compared to the one that LlamaParse generated.
Example 1: Original table from the data file:
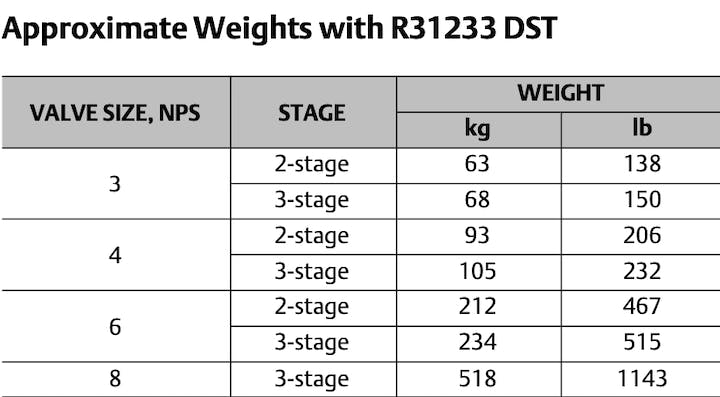
The same with GPT-4-vision based pdf2md.py:
``` ### Approximate Weights with R31233 DST | VALVE SIZE, NPS | STAGE | WEIGHT | |-----------------|---------|--------| | 3 | 2-stage | 63 kg | | | | 138 lb | | | 3-stage | 68 kg | | | | 150 lb | | 4 | 2-stage | 93 kg | | | | 206 lb | | | 3-stage | 105 kg | | | | 232 lb | | 6 | 2-stage | 212 kg | | | | 467 lb | | | 3-stage | 234 kg | | | | 515 lb | | 8 | 3-stage | 518 kg | | | | 1143 lb | ```
LlamaParse (on 26th February, 2024):
``` |Approximate Weights| |---| |VALVE SIZE, NPS|STAGE|kg|lb| |2-stage|63|138| |3|3-stage|68|150| |4|2-stage|93|206| | |3-stage|105|232| | |2-stage|212|467| |6|3-stage|234|515| |8|3-stage|518|1143| ```
Example 2: Table on page 45:
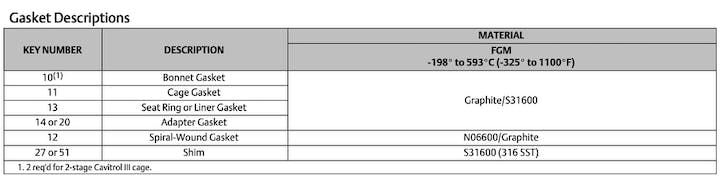
GPT-4-vision based pdf2md.py:
``` ## Gasket Descriptions **KEY NUMBER** | **DESCRIPTION** | **MATERIAL** -------------- | ---------------------------------- | --------------------------------- 10(1) | Bonnet Gasket | Graphite/S31600 11 | Cage Gasket | 13 | Seat Ring or Liner Gasket | 14 or 20 | Adapter Gasket | 12 | Spiral‐Wound Gasket | N06600/Graphite 27 or 51 | Shim | S31600 (316 SST) _Note:_ | _2 req'd for 2‐stage Cavitrol III cage._ | (1) The number in parentheses corresponds to the footnote indicating that 2 units are required for the 2-stage Cavitrol III cage. **MATERIAL Key:** - FGM: Service Temperature Range from -198°C (-325°F) to 593°C (1100°F) ```
LlamaParse (26th February, 2024):
``` |KEY NUMBER|DESCRIPTION|MATERIAL| |---|---|---| |10(1)|Bonnet Gasket|-198 to 593 C (-325 to 1100 F)| |11|Cage Gasket|Graphite/S31600| |13|Seat Ring or Liner Gasket| | |14 or 20|Adapter Gasket|Spiral-Wound Gasket N06600/Graphite| |27 or 51|Shim|S31600 (316 SST)| |1. 2 req'd for 2-stage Cavitrol III cage.| | | ```
Overall LlamaParse did not do so well with the more complex tables.
Example 3: Images inside document
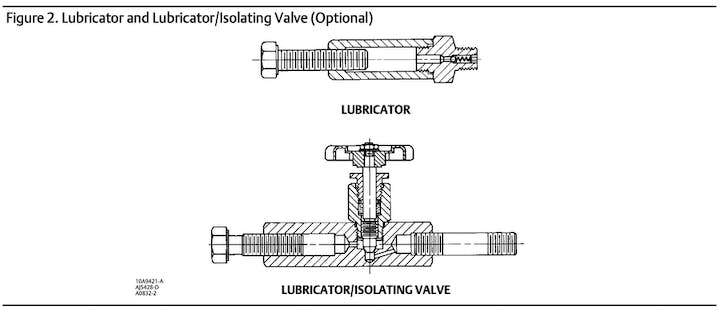
GPT-4-vision based pdf2md.py:
``` **Figure 2. Lubricator and Lubricator/Isolating Valve (Optional)** A technical drawing exhibits two configurations of a valve system. The first configuration shows a "Lubricator," a streamlined assembly with connections for the flow of lubricant. Annotations indicate various parts and arrows show the path of the lubricant. The second configuration, labeled "Lubricator/Isolating Valve," appears more complex with added valves and mechanisms for an isolation function. Both configurations are depicted in a side-by-side view with sectional drawings that provide insight into their internal structures, including details on threading and part linkages. ```
LlamaParse (26th February, 2024):
``` Figure 2. Lubricator and Lubricator/Isolating Valve (Optional) |LUBRICATOR|LUBRICATOR/ISOLATING VALVE| |---|---| |10A9421-A|AJ5428-D| |A0832-2| | ```
LlamaParse extracted the texts from the figure. Whereas GPT-4-Vision based approach can describe the images, but failed on detecting the small printed ids.
Conclusion
Multimodal models are going to open up doors for computers to digest information that was out of reach before. Using visual capabilities together with more structural views seem like the way to go. It overcomes the fuzzy nature of image recognition and allows us to get more reliable results. Using an LLM in the process also raises new concerns that we need to think about when building and using these tools. LLM does not just copy data, instead it is interpreting it. Interesting to see what the future will bring, when computers are becoming more and more capable. If you are interested in experimenting with this approach the code is at https://github.com/robocorp/llmfoo/blob/master/src/llmfoo/pdf2md.py